
インスタグラムのQRコード(ネームタグ)の表示・加工方法から、スキャン・シェア方法まで解説します
インフルエンサーマーケティング
2022.12.23
![]()
2018.03.29
2022.12.23

bz2, xz, Deflate, gzip, zip, snappy, …データ圧縮に関しての名前です。
なんとなく見覚えがあるだけのものから、普段使いしているものまで色々あって、なんとなく使ってはいるけれど、それぞれどのような意図を持って使い分けたら良いのでしょうか。そもそもどんな違いがあるのでしょうか。
この違いがちゃんとわかっていたら、なんとなくかっこいい気がしませんか?というわけで、今回は圧縮アルゴリズムの歴史と、特性を追っていきたいと思います。
圧縮をまず大きく大別すると、可逆圧縮と非可逆圧縮に分けられます。その名の通り、元に戻せる圧縮方法と、元には戻せない圧縮方法です。非可逆圧縮の用途には音声、画像や動画などの圧縮があります。
データとしてはわざと欠落させるけれど、人間の認識には影響の少ないようにするものがあります。用途、画像でよく使われるJPEGや動画でよく使われるMPEG-2などが非可逆圧縮になります。
2017年末に日本でもローンチされた音楽ストリーミングサービスのDeezerは可逆圧縮(ロスレス)で音楽を配信するため、データを欠落させていないので高音質と言われています。
非可逆圧縮も日々進歩していますが、今回は可逆圧縮について掘り下げて行きたいと思います。
可逆圧縮は元に戻せる圧縮方式ですが、その方法はざっくりいうとデータの中に冗長な部分や特徴を見つけて、そこを元に戻せる形で削減する方法です。
可逆圧縮で人間にも理解しやすい方法として、ランレングスというのがあります。日本語だと連長圧縮と言われていたりする、同じものが連続している部分に注目して圧縮する方法です。
例えば、
a a a a a a a a b b b b b b c c
というデータがあったとします。このデータをランレングス法によって圧縮すると
a 8 b 6 c 2
というような表し方ができます。
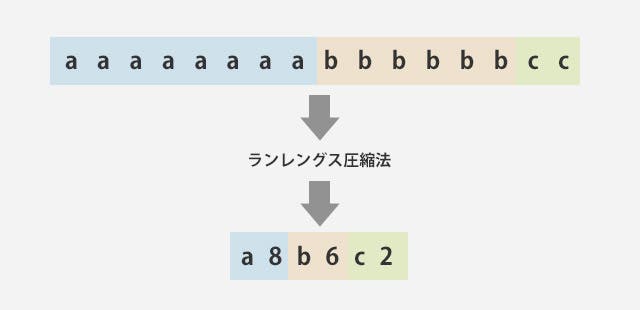
この方法は同じ値が連続することが多く、出現する値の種類が少ない場合に非常に使いやすく、画像やFAXなどで使いやすい圧縮の方法になります。
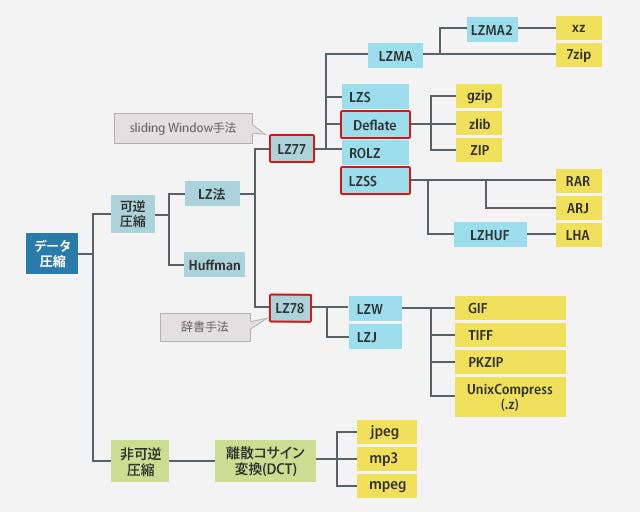
「Abraham Lempel」と「Jacob Ziv」の二人によって 1977年に誕生したLZ77と、その翌年に同じ原理でありながら、別の手法を使ったLZ78があります。
1977年と40年も前に誕生した原理でありながら、今現在も使われている圧縮の方法の多くはLZ法を改良したものになっています。
LZ77はLZ法の初期のアルゴリズムで、1977年に誕生しました。既に出てきている文字の並び(単語)が再度出てきたら、それをより短い符号に置換えていくというアルゴリズムです。
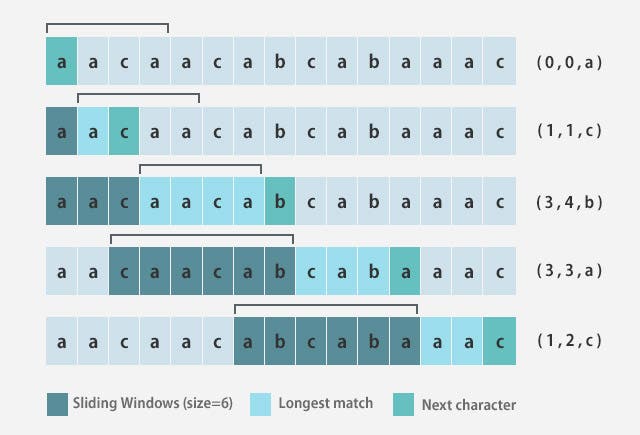
しかし、事前に出てきたデータをすべて検索し、符号化しようとするとすべてをメモリに載せるもしくは、何度も読み込みなおす必要が出てきてしまうため、圧縮の速度に影響を及ぼしてしまいます。そのため、sliding windowsというどの程度遡るかを決めるウィンドウを設けて現実的な速度を確保しています。
LZ78はLZ77の翌年に誕生したアルゴリズムで事前に出てきたデータを符号化するという点では同じなのですが、LZ77との違いとして辞書を利用します。辞書を利用する利点としては、LZ77ではsliding windowsと呼ばれるある範囲のみ遡って符号化しますが、LZ78の場合は明示的に破棄しない場合は出現したものすべてを辞書として保持します。
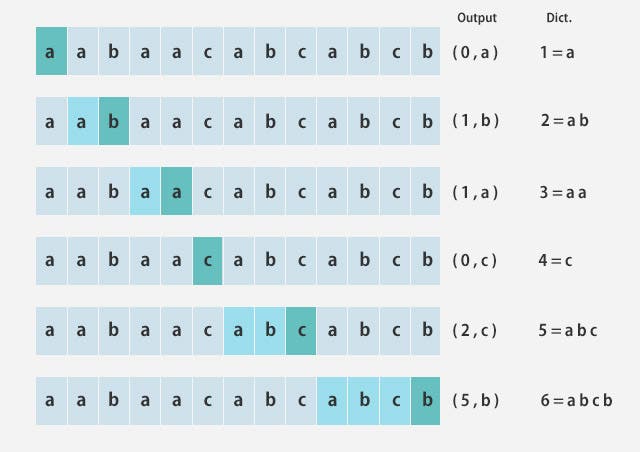
ここまでで上げたLZ77とLZ78が大きく2つの源流となっており、辞書型とsliding window型と呼ばれています。
LZ77を元に、不一致だったとしても符号化してしまい長くなってしまうという点を修正しています。この修正によりLZSSは劇的な性能向上を果たしており、現在の圧縮プログラムで多く使われるアルゴリズムになっています。
圧縮アルゴリズムでLZ77と書かれている場合でも実装はLZSSが使われていることもあります。
LZ77系で私の主観として最も普及しているのがDeflateです。Deflateと聞いてもピンと来ないかもしれませんが、gzip, zip と言えばどれくらい普及しているか想像がつくのではないでしょうか。
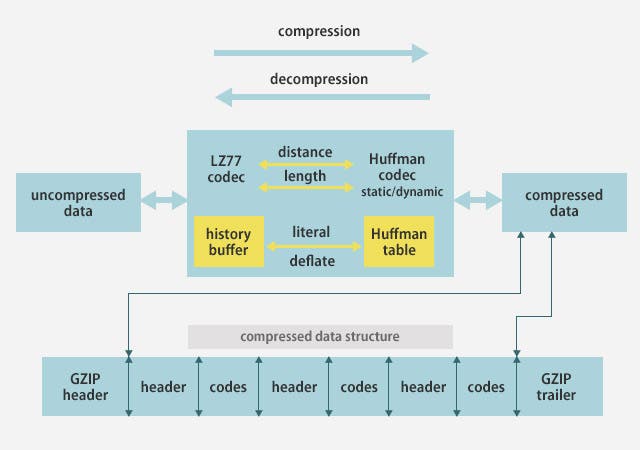
deflateは、LZ77(実際にはその変種のLZSS)でデータを「文字そのもの」または (一致長, 一致位置) ペアに符号化する。その結果のうち、「文字そのもの」および「一致長」を合わせて一つのハフマン符号で符号化し、「一致位置」を別のハフマン符号で符号化する。deflateのハフマン符号化は、ブロック毎に符号を(再)構築する方式で、ダイナミックハフマン符号(英: Dynamic Huffman coding)と呼んでいる。
引用: wikipedia
以下の図は圧縮、伸張の流れを表しています。
LZ78を元に作られたアルゴリズムでありますが、アルゴリズムどうこうというよりも、特許によって業界に旋風を巻き起こしました。
LZWの開発者の一人である、Terry Welch(LZWのWはWelchのW)は当時Sperryという会社の従業員であり、LZWの特許はSperryという会社が保有していました。その後SperryはBurroughsと合併し、Unisysとなり、LZWの権利もUnisysが持つことになります。Unisysになっても、LZWの利用に関し利用料を請求しないとしていたため、LZWはgifやtiffなどの画像の圧縮方式として普及していきました。
ところが、普及した後にUnisysは「LZWを用いてGIFを生成する機能を持つすべて商用ソフトウェアにライセンス利用の支払いを求める」と言い出したのです。単なる圧縮アルゴリズムであればよかったのですが、広く普及したgifという画像フォーマットに使われているために、大きな騒動になっていきました。
最初は商用ソフトウェアに限定されていたものも一段落すると、今度はフリーソフトウェアにまでこの権利を主張し始めます。さらに、ライセンス料を支払っていないソフトウェアで作られたgifに関しては利用者からライセンス料を徴収するとまで言い出したので、手におえません。
そんな中GNUプロジェクトは早期にUnix由来のファイル圧縮プログラムのCompress(LZW) を捨て、GNU zip (gzip)をリリースしています。画像についてもいち早くgifではなく、pngを推奨していました。
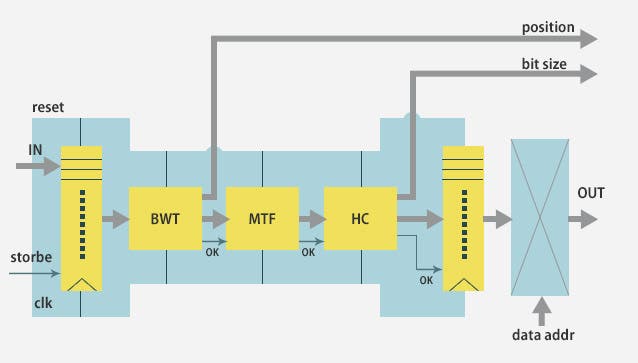
LZ Familyには入りませんが,ブロックソート、MTF、ハフマン符号化を組み合わせた圧縮方法で、圧縮率がDeflateよりも高かったことと、動作の安定性で高く普及しました。しかし、Deflateに比べると、圧縮伸張時間で劣るため完全に置き換えるものではないが、OSのイメージや各種パッケージの配布などで利用されています。
bzip2は2となっていますが、もともとbzipというソフトウェアを開発していました。しかし、bzipで利用していた算術符号化は抜け穴が無いと言われる程に特許がとられており、算術符号化は使えないという事で開発を断念しています。
算術符号化の部分をハフマン符号化に置換えbzip2になったという経緯があります。この算術符号化についてはのちにRange Coderによって解決されていきます。
LZ77を祖先に持ちますが、比較的新しい圧縮アルゴリズムとなっています。
後半にRange Coderを利用することで、圧縮に時間はかかるが伸張の時間は短く、さらに圧縮率はDeflate やbzip2よりも高いという特徴があります。Range Coderは算術符号を利用していますが、特許に抵触しないように作られており、安心して使える算術符号です。
冒頭にあった bz2, xz,Deflate, gzip, zip, snappy, … といった文字列がここまで出てきていないですね。
ここまでのお話は圧縮のアルゴリズムであり、どのようにデータを圧縮するかという話でした。しかし実際にコンピュータ上で使う時にはファイルとして扱う事も多く、圧縮プログラムはファイルとして出力することができるものが多いです。ここまでに出てきたアルゴリズムはDeflateであればlibzというライブラリにまとまり、gzipという圧縮プログラムで使用されています。
xzや7zと言った新しめの高圧縮プログラムではLZMA2,LZMAというアルゴリズムが利用されています。bzip2の場合はアルゴリズムと圧縮プログラムがほぼイコールですが、他の圧縮プログラムについては圧縮プログラムと圧縮アルゴリズムに別名が付いていることが多いです。
この関係性を覚えておくことで、実は解凍できてしまうものがあったり、圧縮プログラムのライセンスの違いをすり抜け利用することができたりします。
【コラム:アーカイバ】
圧縮のプログラムはデータの圧縮は行うけれど、ファイルをまとめる機能を持っていないことがほとんどです。.tarという拡張子を見たことは無いですか?
.tar.gzやtar.bz2といった形で目にする事が多いかと思います。これはtarというアーカイバプログラムで複数ファイルを1つのファイルにまとめ、まとめたものをgzipやbzip2で圧縮しています。
この1つのファイルにまとめるプログラムのことをアーカイバと呼びます。zipというプログラムはアーカイバと圧縮プログラムの両方を兼ね備えた便利なツールになっています。
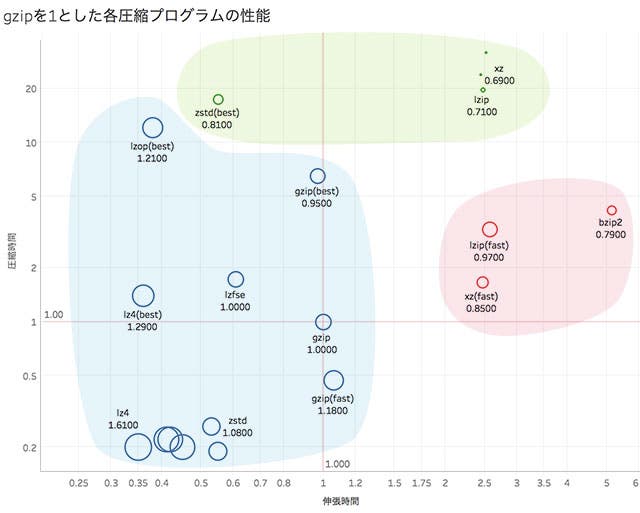
圧縮のアルゴリズムは圧縮率の高さと圧縮/伸張速度とのトレードオフになっています。
大きなファイルをインターネット越しで配布する場合、圧縮するのは一回に対して、複数回ダウンロードされるので、速度よりも圧縮率の高さを優先します。
サイトの閲覧のように小さいデータを高速に圧縮・伸張する必要がある場合には速度を優先したいので、Deflateのような圧縮率よりも圧縮、伸張時間が速いアルゴリズムを利用します。Apacheのmod_deflateというモジュールを触ったことのある人もいるのでは無いでしょうか?
今回は紹介しませんでしたが、Facebookが開発したzstdやGoogleが開発したSnappyなども高速な圧縮アルゴリズムとして出てきています。こういった圧縮のアルゴリズムの違いを理解しておくことで、ネットワークの帯域を節約したり、もしくはコンピューティング能力の節約をすることが可能となってきます。
クラウド時代、そこまで気にすることはなくなってきましたが、今一度改めて圧縮について学ぶことで、コストを削減することが可能かもしれません。

2015年に業務委託としてJuicerのインフラの構築、その後コンサルティング契約を経て、2017年に中途入社。Juicer事業部でJuicerが持っているデータに価値を与える仕事に従事。
インフルエンサーマーケティング
2022.12.23

インターネット広告
2023.12.22

SEO対策
2024.04.17

SEO対策
2024.04.10

SEO対策
2024.04.17

Webサイト制作
2023.05.11

インターネット広告
2024.03.05

SEO対策
2024.04.25