
インスタグラムのQRコード(ネームタグ)の表示・加工方法から、スキャン・シェア方法まで解説します
インフルエンサーマーケティング
2022.12.23
![]()

2017.11.17
2022.12.23


※フォーム送信後、メールにて資料をお送りいたします。
弊社の会社概要と、ケイパビリティのご紹介資料です。ご覧いただき、お気軽にお問い合わせください。
※フォーム送信後、メールにて資料をお送りいたします。

フォームでの問い合わせが
完了いたしました。
メールにて資料をお送りいたします。
2010年ごろから耳にし始め、2013年-2014年頃にバズワード化したのがビッグデータです。
最近では世の中に浸透して、ビッグデータの活用方法が色々と世の中に出ていますが、ビッグデータとはなんなのか?どのようなデータをビッグデータと呼ぶのか、今一度整理してみたいと思います。
ビッグデータとは大量のデータという意味だけではなく、それ以外の要素も含んでいると個人的には感じております。まず、一般的なビッグデータの特性を3つのVで表してみます。
1年間ほど徐々に増えていくデータを見守ってきた感覚から、3つのVに加えてビッグデータとは子供のおもちゃ箱のようなデータで、以下のような特徴もあると個人的に思います。
ビッグデータを活用してできることは様々です。以下にいくつか例をあげました。
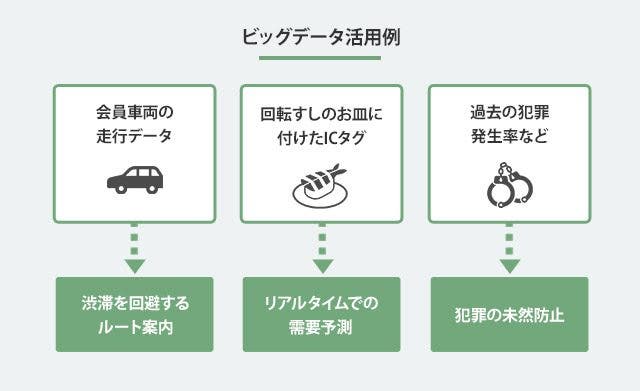
会員車両から送信される走行データを分析して渋滞を回避するルート案内を提供しています。毎月送信される走行データは毎月1億キロにのぼるようです。
回転すしのスシローではお皿につけたICタグによる鮮度管理とタッチパネルを用いた人数管理(大人・子供)によってリアルタイムでの需要予測を行っているようです。
米カリフォルニア州サンタクルーズ市では犯罪が発生する場所や時間帯を予測し、犯罪を防ぐ試みを行っています。分析するデータとしては犯罪発生率、前科者の有無、街灯の有無などになります。
結果としては17%犯罪が減少しているようです。マイノリティ・リポートのような未来に近づいている気がします。
メジャーリーグベースボール(以下MLB)では全てのプレイのデータをすばやく取り込みリアルタイムに分析し提供しています。
上で紹介しただけでも、交通・飲食・公共・スポーツなど様々な分野で利用されています。その他にも通信・金融・流通・運輸・小売・製造・医療・農業などでも利用されています。
ビッグデータの分析手法には色々ありますが、Hadoopが良く利用されています、実際の分析にはHadoop上で動作するHiveなどを利用して分析を行います。HiveはSQLを使用することができるので、分析がかなりカジュアルになります。
その他にもHadoop上で動作するPrestoなどもあります。Prestoはメモリ上にデータを展開するので、Hiveに比べて高速にデータを処理することが可能です。以下に分析の流れと種類をまとめました。
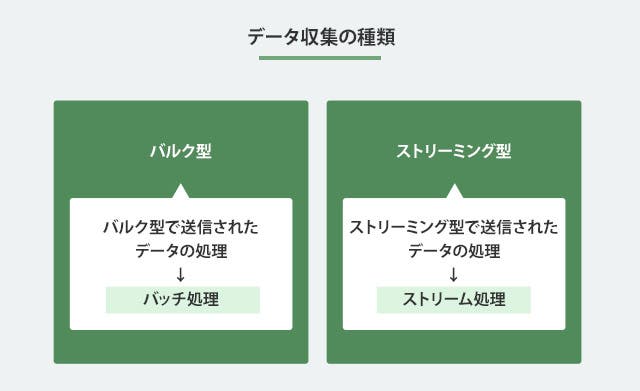
大別してデータ収集はバルク型とストリーミング型に分けられます。
従来はバルク型の方法が用いられてきましたが、最近ではモバイルアプリの増加やIotなどから送信されるセンサーデータの増加などから、ビッグデータの世界ではストリーミング型の手法が多く用いられています。
ストリーミング型で送信されたデータはリアルタイムに処理します。これをストリーム処理と呼びます。また、バルク型で送信されたデータを処理することをバッチ処理と呼びます。それぞれの処理には以下のような特徴があります。
ストリーム処理はリアルタイムに処理を行うため、中長期的なデータの処理には向きません。リアルタイムに集められたデータを一定の間隔で処理します。
一方で、例えば1日分の処理をまとめて行う場合などはバッチ処理を用います。これをクエリエンジンに少し乱暴に当てはめると、リアルタイムに処理する場合のクエリエンジンにはPrestoを用いて、1日分のデータを処理する場合にはHiveをクエリエンジンに用います。
最近はHive、Presto以外にも選択肢はたくさんあります、AWSなどを使っている場合はKinesis Streamsとkinesis Analytics などを組み合わせたり、EMRを用いた分析手法も考えられます。
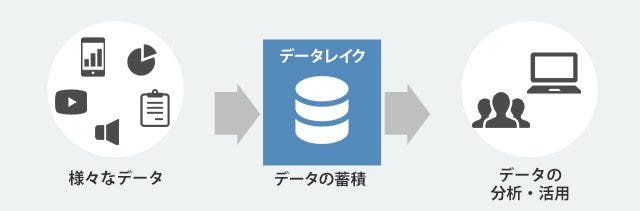
データレイクとはデータを貯めておく場所の事です。個人的にはデータをほぼ無尽蔵に貯めておけて、データを取り出す仕組みがある場所であればなんでもよいかなと思います。AWSサービスでいえば、S3が一番用途に適しているかと思います。
データ形式に関してもCSV、JSONなどがありますが、形式がそろっていれば良いかと思います。1つだけルールがあるとすれば、生データが保存されているということです。
データレイクに対してデータマートは加工されたデータの保存場所です。一般的にはMysqlやPostgreSQLなどのRDBMSが思いつきますが昨今はもっと選択肢があります。
データマートは主にダッシュボードや、BIツールなどから参照される事を想定しています。またデータマートに対しても分析を行う事もあり、分析手法としてはSQLが多く用いられます。
ビッグデータの分析にはパターンのようなものが存在し、すべてが当てはまるわけではありませんが、パターンに当てはめて考えることで効率よくビッグデータを処理できます。
上記のようなワードがビッグデータを取り巻く今後かなと思います。今後は様々な形でビッグデータ分析がもっとカジュアルになり、データサイエンティストだけの物ではなくなって来るかと思います。
一方でデータ量は増加し、データ種類は複雑化することが予想され、さらにリアルタイム化とスピードが求められるでしょう。
ビジネス分野でもAIが取って代わる分野も今後出てくるかと思います。ビッグデータに関する見解は様々ではありますが、個人的には昔映画で見た世の中に近づいていることにすごくワクワクしています。
弊社の会社概要と、ケイパビリティのご紹介資料です。ご覧いただき、お気軽にお問い合わせください。
フォームに必要事項をご記入いただくと、
無料で資料ダウンロードが可能です。
資料請求
ありがとうございました。

インフルエンサーマーケティング
2022.12.23

インターネット広告
2023.12.22

SEO対策
2024.04.17

SEO対策
2024.04.10

SEO対策
2024.04.17

インターネット広告
2024.03.05

Webサイト制作
2023.05.11

SEO対策
2024.04.25