
非公開: SEO対策とは?SEOで上位表示する効果的な施策と事例
SEO対策
2023.09.26
![]()

2017.09.26
2023.05.31


※フォーム送信後、メールにて資料をお送りいたします。
専属のコンサルタントが貴社Webサイトの課題発見から解決策の立案を行い、検索エンジンからの自然検索流入数向上のお手伝いをいたします。
※フォーム送信後、メールにて資料をお送りいたします。

フォームでの問い合わせが
完了いたしました。
メールにて資料をお送りいたします。
サイト上のクロールされたくないコンテンツを制御するファイルであるrobots.txt。こちらが適切に設定されていることで、重要度の高いコンテンツが優先的にクロールされ、サイト全体のSEOにも良い効果があると言われています。
robots.txtを使用していないと、必要の無いページまで検索エンジンにクロールさせて、サイト全体のクオリティを下げている可能性が高いです。
本記事をご活用し、そもそもの役割を理解し、適切な設定を行っていただければと思います。
robots.txtとは、収集されたくないコンテンツをGoogleといった検索エンジンによってクロールされないよう制御するファイルを指します。
一般的にはクロールされることは良いと捉えられることから、「WEBページにある全てのコンテンツはクロールされた方がいいのでは?」と考える人もいるかもしれません。
しかし、会員限定のコンテンツやショッピングカート、またシステム的にやむを得ず自動で生成されてしまう重複ページなどはクロールさせることで、かえってサイト全体のSEOに影響が出ることがあるのです。
robots.txtを導入することで、無駄なページへのクロールを制限でき、クロールの最適化も見込め、サイト内の重要なコンテンツへのクロールが優先されるようになります。
サイト内の重要なコンテンツはすなわち、ユーザーにとっても価値あるコンテンツであると言えるので、
その結果、短期間でWEBサイト全体のSEOにも効果的だとされています。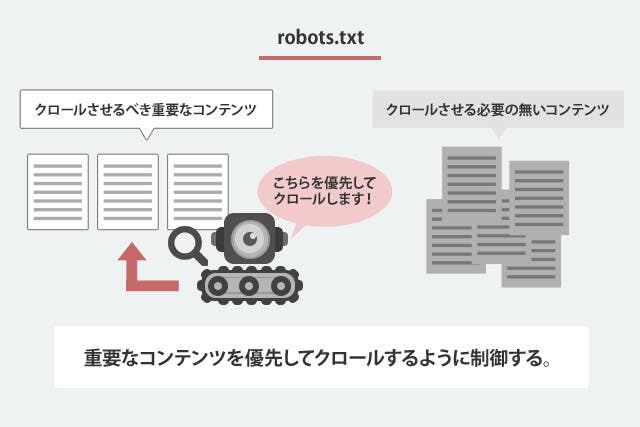
「robots.txt」と「noindexタグ」は、どちらも検索エンジンのクロールやインデックスを制御するための指示ですが、それぞれの使い方に違いがあります。
まず、「robots.txt」はテキストファイルで、特定のディレクトリやページ単位で検索エンジンのクロールを制御するために使用されます。このファイルに記載されたディレクトリやページは、検索エンジンのクローラーに対してアクセスを不可とすることができます。
一方、「noindexタグ」は、HTMLタグとして特定のページに追加され、そのページが検索エンジンの検索結果に表示されないようにするために使用される機能です。つまり、クロールは実行されますが、インデックスに加えないため検索結果には表示されなくなります。
このように、どちらも検索エンジンに対して制御をかけることができますが、robots.txtはアクセスを制御するのに対して、noindexタグは検索結果に表示させないための指示に使われます。適切に使い分けることで、WebサイトのSEO対策をより効果的に行うことが可能です。
robots.txtは非常に強い指定のため、誤った記述をしてしまうとWebサイトに重大な問題を引き起こす危険性があります。
せっかく良質なコンテンツを作成しても、誤ったrobots.txtの作成によって上手くクロールされなかったらもったいないですよね。
そのような事態に陥らないためにも、適切なrobots.txtの記述方法を知ることが大切です。
これからrobots.txtの正しい書き方についてご説明します。
robots.txtを作成するのに特別なツールは必要なく、誰でもメモ帳で作成できます。
記載内容は、主に「User-agent」「Disallow」「Allow」「Sitemap」の4つあり順に説明します。User-agentだけは必須で記入しなければなりません。
まずは、robots.txtの基本の書き方の例をご覧ください。
|
1 |
User-Agent:* Disallow: Sitemap:http://example.com/sitemap.xml |
上記の様な形でtxtファイルに記述をします。各記述の説明は以下の通りです。
User-Agentという記述は対応する検索ロボットを意味します。
「*」を使用した場合は、全ての検索エンジンロボットを指定することができます。
Googleのクローラーのみを指定したい場合は「User-Agent:googlebot」と記述し、その他特定のクローラーを指定する際には、それぞれに対応した記述をしましょう。
▼User-agentの記入例
User-agent : * →全てのクローラーが対象
User-agent : Googlebot →Googleのクローラーのみ対象
User-agent: bingbot →Bing検索のクローラを対象します
User-agent : Baiduspider →百度(バイドゥ)のみ対象
その他のUser-Agentは、以下を参考にしてください。
Disallowという記述はアクセスの拒否を行う際に使用します。
上記の例の様に、Disallow:の後に何も記述をしなければ、アクセスが拒否されることはありません。
使用方法としては、Disallow:の後にアクセスを拒否したいルートディレクトリ、またはファイル名を指定します。
例えば、http://example.com/login/の/login/以下のページ全てに対してアクセスを拒否する場合は「Disallow:/login/」と記述します。
また、ルートディレクトリ以外にもパラメータ付きURLに対するアクセス拒否も可能です。その場合は「Disallow:/*?example=*」のexampleの部分をそれぞれのパラメータに変更してご利用ください。
このようにクロールの必要が無いページに対しては、Disallowを記述し、クロールの制御を行いましょう。よく行われている例としてはログインURLなどが対象になります。Wordpressの管理画面のURL(例aaa.com/wp-admin)をクロール拒否しているサイトは多数あります。
▼Disallowの記入例
Disallow : / →サイト内の全てのページをブロック(/はTOP配下全てを表す)
Disallow : →ブロックなし
Disallow : /directory1/page1.html →ページ(/directory1/page1.html)のみブロック
Disallow : /directory2/ →ディレクトリ(/directory2/)配下全てのページをブロック
Allow : /directory2/page1.html →ページ(/directory2/page1.html)のみクロール許可
Sitemapは、Sitemap.xmlを設置しているページを絶対パスで指定できる記述です。
Sitemap.xmlを記述することで、検索エンジンに対しsitemap.xmlの存在を伝えることができます。
特に設定しておかなくても、勝手に検索エンジンロボットはクロールしてくれますが、robots.txtに記述しておくことで余計なページを巡回させずに済みます。robots.txtを利用して、クローラーに快適な巡回をさせてあげましょう。
▼sitemapの記入例
Sitemap : https://croja.jp/sitemap.xml
Sitemap : http://example.com/index_sitemap1.xml
※sitemap.xmlのファイル名は「sitemap.xml」以外でも機能します。
書き方の例には記載しておりませんが、Allowという記述をすることでアクセスの許可を促すことができます。
ただ何も記載しない状態がアクセス許可を意味するため、この指定を使用する機会は少ないでしょう。
Allowを利用するのは、Disallowでブロックしているディレクトリ内の一部のページだけクロールさせたい場合などです。
▼Allowの記入例
Allow : /directory2/page1.html ※ページ(/directory2/page1.html)のみクロール許可
robots.txtの作成方法がわかったところで、実際に作成する場合に注意すべきポイントを3点ご説明します。
メリットがある反面、リスクもあるので注意事項もきちんと把握していおきましょう。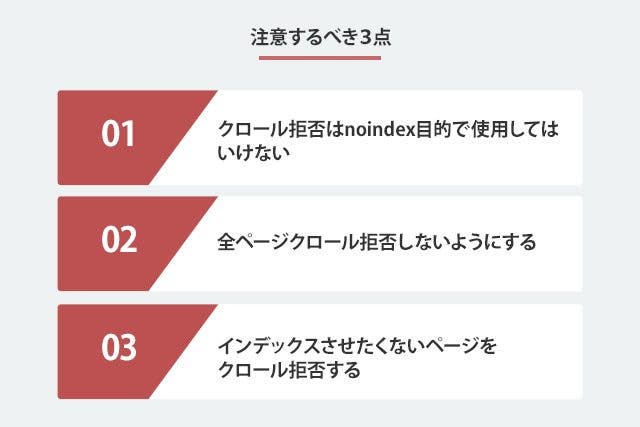
1つ目は、クロール拒否はnoindex(インデックスされない)目的で使用してはいけないことです。あくまでクロール拒否はクロールを拒否する役割であり、インデックスが防げるわけではないためです。
robots.txtにdisallowの指定をすると、クロールのアクセスを制御することができるため、基本的にはインデックスされることはありません。
しかし、他ページにdisallow対象のページへのリンクが設置されている場合に、インデックスされてしまう可能性があります。
絶対にインデックスさせたくないページには、head内に以下の様にnoindexを使用しましょう。
noindexを促すrobotsメタタグ
|
1 |
<meta name="robots" content="noindex" /> |
2つ目の注意点は、全ページをクロール拒否しないようにすることです。
robots.txtを作成する上で最も危険な行為が、全ページをクロール拒否してしまうこと。
以下の記述は、クロールを全て拒否してしまうため、絶対に使用しないようにしてください。
|
1 |
User-agent: * Disallow: / |
robots.txtを設定した際には、上記の記述をしていないかどうかをチェックしましょう。
3つ目は、インデックスさせたくないページのクロール拒否を忘れないという点です。
不要なページをインデックスさせないために、robotsメタタグでnoindexの指定したページをDisallowでクロール拒否をしてはいけません。
クローラーはnoindexの記述を確認する必要があります。
既に検索結果に表示されている場合、クロールを拒否されているとそのページはインデックスされ続けてしまいます。
4つ目は、robots.txtを変更した場合、変更が検索エンジンに反映されるまでに時間がかかることがある点です。Googleは数日から数週間かかる場合があります。そのため、robots.txtを変更した場合は、変更がすぐに反映されないことを覚悟しておく必要があります。
また、robots.txtを設定したタイミングだけではなく、解除する際にも同様に時間がかかることを理解しておきましょう。
5つ目は、robot.txtを指定してもユーザーは閲覧できることです。robots.txtファイルは、検索エンジンのクローラーがWebサイトの特定ページをクロールしないようにするために使用されます。しかし、アクセスした一般ユーザーには、Webサイトのコンテンツが表示されることがあります。
つまり、Webサイトのページを完全に非表示にしたい場合は、他の方法を検討する必要があります。具体的には、コンテンツ自体を削除したり、非表示にしたりすることで、ユーザーに閲覧されない状態を作ることが重要です。
robots.txtの作成が完了したら、次はサーバーにアップロードしましょう。
アップロードする際は、サイトのトップディレクトリに設置してください。
robots.txtは各種サーバーのコントロールパネルから設置、またはFTPクライアントを利用してください。主なFTPクライアントは以下の通りです。
■Windows用
■Mac用
robots.txtは、sitemap.xmlと同じ階層にアップロードしましょう。
正しい例: https://example.com/robots.txt
ダメな例: https://example.com/blog/robots.txt
WordPressサイトでは、インストールするだけでrobots.txtが自動で生成されます。
WordPress標準のrobots.txtでは、次のように管理ツールのクロールを拒否する設定がされています。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
ただし、FTPクライアントなどでファイルを見ても、実際にrobots.txtファイルは存在しません。そのため、仮想robots.txtと呼ばれています。
WordPressで自動生成されたファイルは、デフォルトの状態ではログイン画面がアクセス拒否されているだけで、記述の追加修正が必要な場合があります。
その際には管理画面から修正が可能となる、便利なプラグインを利用しましょう。
プラグインの新規追加から「WordPress Robots.txt File」をインストールして、有効化します。
すると、管理画面メニューの表示設定にrobots.txtを編集できる項目が追加されますので、任意の記述を記載します。
ちなみに、プラグイン有効化前のデフォルトの状態ではSitemap: http://example.com/sitemap.xmlの記述はありませんので、忘れずに追加をしましょう。
または「Google XML Sitemaps」や「All in One SEO Pack」というプラグインをインストールすることで、自動的にXMLファイルの指定が可能です。
robots.txtの設定が完了した後、サーチコンソールを利用して正しく設定されているかチェックします。
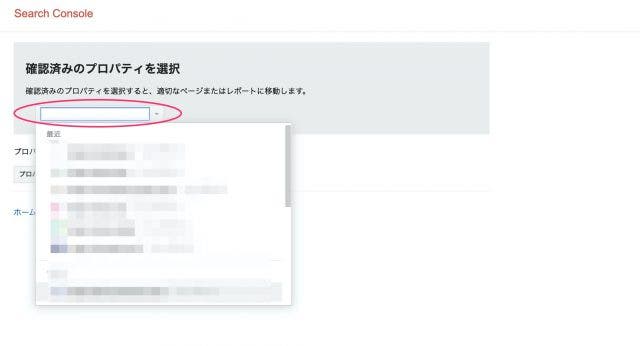
「robots.txtテスター」を選択しプロパティを選択します。
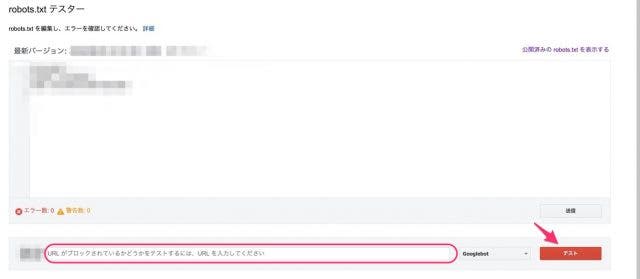
テキストボックス内にrobots.txtを設置しているURLを記入し、テスト対象のユーザーエージェントを指定して「テスト」ボタンを押します。
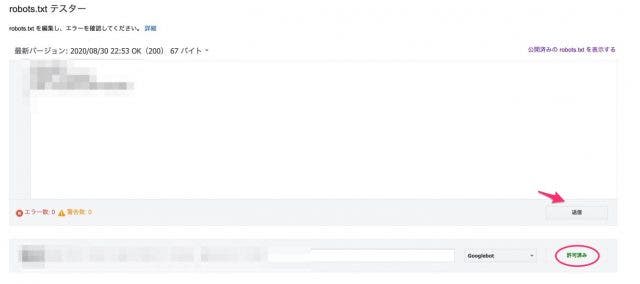
テスト結果で問題が無ければ、Googleにrobots.txtの更新情報を知らせましょう。
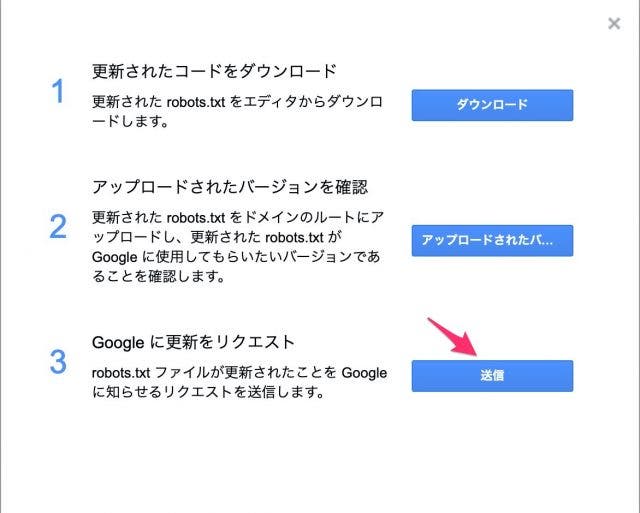
「送信」ボタンをクリックするとダイアログが開きますので、3つ目の項目にある「Google に更新をリクエスト」の「送信」を押してrobots.txtの設置は完了です。
ここまでrobots.txtの正しい設定方法と、その役割について紹介しました。
クロール頻度を上げる行為自体は、検索結果のランキングに直接影響を与えることはありません。
しかし重複コンテンツなどの質の低いページが多くクロールされることで、重要なページへのクロールが遅れる可能性があります。
robots.txtを使用して、優先度の高いページへのクロールを促進し、検索アルゴリズムに好かれるサイト構築を目指しましょう。
SEOをもっと学びたい方はこちらもチェック:SEO対策の全てを紹介!
SEOの内部対策についてはこちらもチェック:SEO内部対策を徹底解説!


専属のコンサルタントが貴社Webサイトの課題発見から解決策の立案を行い、検索エンジンからの自然検索流入数向上のお手伝いをいたします。
フォームに必要事項をご記入いただくと、
無料で資料ダウンロードが可能です。
資料請求
ありがとうございました。

SEO対策
2023.09.26

SEO対策
2023.09.15

SEO対策
2023.10.30

SEO対策
2023.09.15

SEO対策
2024.04.08

SEO対策
2023.09.15

SEO対策
2024.03.15

SEO対策
2024.04.05